In the last few years, software systems have quietly crossed a tipping point. We are no longer running a few applications on a handful of servers; we are operating hundreds of microservices, containers, Kubernetes clusters, managed cloud services, data pipelines, and third‑party APIs—all talking to each other, all changing every day. When something breaks, it rarely breaks in one obvious place. It fails in small, confusing ways across the whole system.This is exactly where Master in Observability Engineering becomes critical. Instead of guessing what went wrong, observability gives you the power to “see inside” your systems using the signals they emit—metrics, logs, traces, events, and profiles. Done well, it turns noisy, scattered data into clear, actionable insight: what failed, where it failed, why it failed, and how it is impacting your users and your business.
What is Observability Engineering?
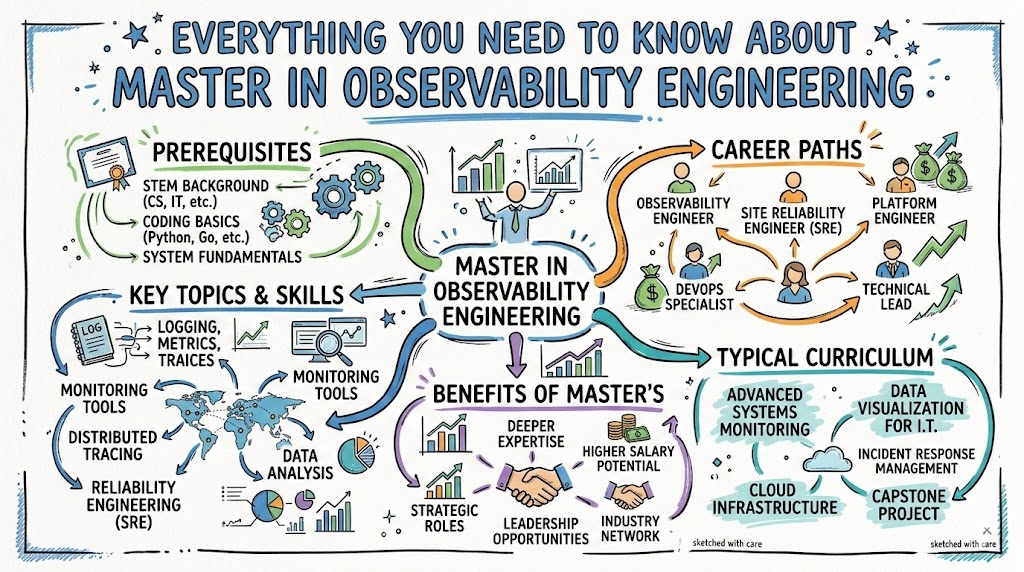
Observability Engineering is the discipline of designing, building, and operating systems that can be understood from the outside using telemetry data such as metrics, logs, traces, events, and profiles. Instead of guessing what is happening inside your application, you create the right signals so that issues can be detected, diagnosed, and resolved quickly.
In modern cloud‑native, microservices, and containerized environments, observability is not optional anymore. It directly impacts uptime, user experience, business revenue, and team productivity.
Why Observability Matters Now
- Systems are distributed across microservices, containers, Kubernetes, and multiple clouds.
- Failures are often partial, intermittent, and difficult to reproduce locally.
- SLAs, SLOs, and error budgets demand measurable reliability.
- Teams must move fast (CI/CD, frequent releases) without breaking production.
A strong observability practice helps you:
- Detect incidents early before customers complain.
- Reduce mean time to detect (MTTD) and mean time to resolve (MTTR).
- Understand performance regressions after deployments.
- Enable SRE, DevOps, and platform teams to work with data instead of guesswork.
Core Pillars of Observability
Most modern observability strategies are built on a few core pillars.
Metrics
- Numeric time‑series data (CPU, memory, latency, error rate, throughput, queue length, etc.).
- Ideal for trend analysis, dashboards, and alerting based on thresholds or anomalies.
Logs
- Structured or unstructured records of events (errors, warnings, info, debug, audit logs).
- Useful for detailed troubleshooting and for understanding what happened before and during an incident.
Traces
- End‑to‑end view of a request as it flows through multiple services and components.
- Essential for microservices, serverless, and complex distributed architectures.
Events and Profiles
- Events: Discrete state changes (deployments, configuration changes, feature flags).
- Profiles: CPU, memory, and performance snapshots at function or line level.
A good Observability Engineer knows how to design, collect, store, analyze, and act on these signals efficiently and securely.
What is the Master in Observability Engineering (MOE) Certification?
The Master in Observability Engineering (MOE) is a specialized, hands‑on certification from DevOpsSchool focused on end‑to‑end observability for modern, cloud‑native systems. It covers fundamentals, tools, architectures, OpenTelemetry, cloud platforms, and advanced topics like AI‑driven insights.
The program is vendor‑agnostic and tool‑rich. You learn using Prometheus, Grafana, ELK/EFK, AWS CloudWatch, tracing stacks, and OpenTelemetry in realistic environments.
What You Learn in Master in Observability Engineering
According to the official curriculum and supporting materials, MOE covers the following major areas:
- Observability fundamentals: Concepts, pillars, patterns, and best practices.
- Telemetry collection: Metrics, logs, traces, events, and profiles.
- Observability tools: Prometheus, Grafana, ELK, AWS CloudWatch, APM suites, and related stacks.
- OpenTelemetry: Architecture, SDKs, collectors, exporters, instrumentation techniques.
- Cloud‑native observability: Kubernetes, microservices, containers, and service mesh visibility.
- Alerting and incident response: SLOs, SLIs, error budgets, escalation flows, on‑call and runbooks.
- Advanced observability: AI/ML‑driven analysis, anomaly detection, capacity insights.
- Practical implementation: Setting up observability for real applications and services.
Who Should Consider Master in Observability Engineering?
The MOE certification is ideal for professionals who are responsible for reliability, performance, and visibility of production systems.
- DevOps Engineers and SREs.
- Platform / Reliability / Production Engineers.
- Cloud and Infrastructure Engineers.
- Application / Backend Engineers moving into SRE or platform roles.
- Security and DevSecOps Engineers who need strong telemetry for detection and response.
- Engineering Managers who must design and govern observability strategy.
If you regularly deal with outages, performance bottlenecks, or complex distributed systems, this program fits you strongly.
Master in Observability Engineering – Certification Overview
What it is
Master in Observability Engineering (MOE) is a comprehensive, practice‑oriented certification that teaches you how to design, implement, and scale observability across modern applications, platforms, and clouds. The focus is on integrating metrics, logs, traces, and events into a coherent strategy tied to SRE principles and business outcomes.
Who should take it
- Mid‑level to senior DevOps / SRE / Platform / Cloud Engineers.
- Software Engineers moving into reliability and production engineering.
- Architects and Engineering Managers responsible for system health and SLAs.
Skills you’ll gain
- Observability design patterns and architectures for microservices and monoliths.
- Instrumentation using OpenTelemetry SDKs and agents.
- Implementing dashboards, alerts, and SLO‑based monitoring.
- Using tools such as Prometheus, Grafana, ELK/EFK, CloudWatch, and tracing backends.
- Root‑cause analysis with distributed tracing and log correlation.
- Incident management, on‑call, and post‑incident review practices.
- Applying AI/ML for anomaly detection and intelligent alerting where appropriate.
Real‑world projects you should be able to do after it
- Design and implement a complete observability stack for a Kubernetes‑based microservices application (metrics, logs, traces, dashboards, alerts).
- Migrate an existing “monitoring‑only” setup to a full observability solution using OpenTelemetry and centralized platforms.
- Build SLO/SLI‑driven dashboards for business‑critical user journeys and automate error‑budget alerts.
- Integrate observability into CI/CD pipelines and deployment workflows, including canary and blue‑green releases.
- Diagnose performance regressions and intermittent failures using traces and correlated logs.
Preparation plan (7–14 / 30 / 60 days)
You can adapt your preparation strategy depending on your current experience level and time availability.
7–14 days: Fast‑track (for experienced engineers)
- Day 1–2: Review observability fundamentals, pillars, and basic tools.
- Day 3–5: Focus deeply on OpenTelemetry concepts, collectors, exporters, and instrumenting existing services.
- Day 6–8: Build or refine a small lab environment using Prometheus, Grafana, and ELK for a sample microservices app.
- Day 9–11: Implement SLOs, SLIs, basic incident workflows, and alert configurations.
- Day 12–14: Attempt a capstone‑style mini‑project and revise core topics.
30 days: Balanced plan (for working professionals)
- Week 1: Concepts, architecture, and tool landscape (metrics/logs/traces, OpenTelemetry basics, cloud‑native observability).
- Week 2: Hands‑on labs with Prometheus, Grafana, ELK, and CloudWatch; implement dashboards and alerts.
- Week 3: Distributed tracing, service mesh observability, and production‑grade pipelines.
- Week 4: Advanced topics (AI/ML in observability, anomaly detection) and a full end‑to‑end project with documentation.
60 days: Deep mastery plan
- Phase 1 (Weeks 1–2): Strengthen foundation in Linux, networking, containers, and Kubernetes (if needed), plus core observability theory.
- Phase 2 (Weeks 3–4): Multi‑tool exposure: Prometheus, Grafana, ELK, cloud services, and at least one APM suite.
- Phase 3 (Weeks 5–6): Complex scenarios—multi‑cluster monitoring, cross‑account cloud visibility, service mesh, and AI‑driven insights.
- Capstone: Implement observability for a realistic application (web + API + database) and simulate incidents.
Common mistakes
- Treating observability as “just monitoring” and focusing only on dashboards, not on instrumentation and data quality.
- Logging everything without structure, which results in high cost and low value.
- Ignoring traces and context propagation in microservices environments.
- Configuring noisy alerts that cause alert fatigue and are eventually ignored.
- Not tying observability to business metrics, SLOs, and clear operational outcomes.
Best next certification after this
After MOE, the best next step typically depends on your career focus:
- For broader platform responsibility: Master in DevOps Engineering (MDE).
- For reliability focus: SRE Certified Professional (SRECP).
- For security and resilience: DevSecOps Certified Professional (DSOCP).
(These are all offered through DevOpsSchool’s ecosystem and align nicely with MOE.)
Certification Table – Master in Observability Engineering
Below is a structured view of the MOE certification itself, with the key details you asked for.
| Track | Certification | Level | Who it’s for | Prerequisites | Skills covered | Recommended order |
|---|---|---|---|---|---|---|
| Observability / SRE | Master in Observability Engineering (MOE) | Advanced practitioner / specialist | Mid‑senior DevOps, SRE, Platform, Cloud, Backend Engineers; Engineering Managers | Basic Linux, networking, one programming language, fundamentals of DevOps/Cloud and monitoring experience | Observability fundamentals; telemetry (metrics, logs, traces); OpenTelemetry; Prometheus, Grafana, ELK, CloudWatch; SLO/SLI design; incident management; AI/ML‑driven observability; cloud‑native and Kubernetes observability | After gaining foundation in DevOps or cloud basics; ideally after hands‑on experience with at least one monitoring stack |
If you want, you can expand this table later with related certifications (MDE, SRECP, DSOCP, etc.) for internal cross‑linking.
Choose Your Path – 6 Learning Paths Around Observability
Observability is not isolated; it connects deeply with DevOps, SRE, DevSecOps, AIOps/MLOps, DataOps, and FinOps. Here’s how to position MOE in six major learning paths, using DevOpsSchool’s ecosystem (including its Master in DevOps Engineering program) as a reference.
1. DevOps Path
- Start: DevOps fundamentals and hands‑on with CI/CD, Git, Docker, basic monitoring.
- Core certification: Master in DevOps Engineering (MDE) for full DevOps lifecycle coverage.
- Specialization: Master in Observability Engineering (MOE) to deepen visibility into your pipelines and platforms.
- Next: GitOps, Kubernetes admin/developer certifications, or SRE‑oriented credentials.
2. DevSecOps Path
- Start: DevOps + application / infrastructure security basics.
- Core: DevSecOps‑focused training and certifications (e.g., DevSecOps Certified Professional).
- Specialization: Use MOE to build strong security telemetry (audit logs, security events, anomaly detection).
- Next: Cloud security or zero‑trust, security analytics, or SOAR‑style operational integration.
3. SRE Path
- Start: SRE principles (SLI/SLO, error budgets, incident response, reliability patterns).
- Core: SRE‑specific training and SRECP certification.
- Specialization: MOE is a natural fit here—observability is the backbone of SRE practice.
- Next: Capacity engineering, performance engineering, chaos and resilience engineering.
4. AIOps / MLOps Path
- Start: DevOps + basic data and ML foundations.
- Core: AIOps / MLOps certifications (AIOps Certified Professional, MLOps Certified Professional).
- Specialization: MOE helps you design telemetry pipelines that feed AIOps engines and ML‑based anomaly detection systems.
- Next: Advanced AIOps platforms, observability data lakes, and intelligent incident automation.
5. DataOps Path
- Start: Data engineering and pipeline fundamentals.
- Core: DataOps certifications and training focused on data reliability and governance.
- Specialization: MOE gives you tools to observe ETL/ELT pipelines, data quality metrics, and job‑level reliability.
- Next: Data SRE, large‑scale data platform observability, and cost optimization for data infrastructure.
6. FinOps Path
- Start: Cloud cost fundamentals and financial operations mindset.
- Core: FinOps Practitioner and related FinOps training.
- Specialization: MOE provides the telemetry foundation that FinOps needs: usage metrics, cost drivers, and performance‑to‑cost correlations.
- Next: Advanced FinOps, multi‑cloud cost governance, and executive‑level reporting.
Role → Recommended Certifications Mapping
Here is a quick mapping to see how MOE fits different roles, based on DevOpsSchool’s certification ecosystem and typical career paths.
Next Certifications to Take After MOE
Referring to the Master in DevOps Engineering (MDE) certification ecosystem and DevOpsSchool’s broader offerings, here are three clear next options depending on your focus.
1. Same Track – Deepen Technical Breadth (DevOps/SRE)
- Master in DevOps Engineering (MDE): Ideal if you come from SRE/observability and now want end‑to‑end DevOps architecture, CI/CD, and infrastructure as code mastery.
- Solidifies your ability to design the entire ecosystem that your observability stack supports.
2. Cross‑Track – Security and Resilience (DevSecOps)
- DevSecOps Certified Professional (DSOCP): Recommended if you want to integrate security deeply into your observability and DevOps workflows.
- You learn to use telemetry for threat detection, compliance, and security posture monitoring.
3. Leadership – Architecture and Strategy
- After MOE and MDE, move toward SRE / DevOps leadership paths, focusing on architecture, reliability governance, and org‑wide practices.
- These tracks prepare you for roles like Principal Engineer, Architect, or Head of SRE/Platform.
Top Institutions for Master in Observability Engineering Training
Several institutions in the same ecosystem offer training and certification support around observability and related tracks. These organizations typically provide instructor‑led courses, self‑paced content, labs, and project‑based learning tailored for working professionals.
- DevOpsSchool – A leading provider focused on DevOps, SRE, DataOps, AIOps, MLOps, DevSecOps, GitOps, and related XOps domains, including Master in Observability Engineering. They emphasize practical, project‑driven learning with real‑world case studies.
- Cotocus – A consulting and training organization that works closely with enterprises on DevOps and SRE transformations. They often leverage DevOpsSchool’s curriculum and frameworks, helping teams implement observability in live environments.
- ScmGalaxy – Specializes in DevOps tools, CI/CD, SCM, and related training. Their programs complement observability education by strengthening your automation and release pipeline fundamentals.
- BestDevOps – An online knowledge and community platform that aggregates content, guidance, and updates around DevOps, SRE, and observability certification paths. It is useful for staying current with trends and opportunities.
- DevSecOpsSchool – Focuses on DevSecOps and security‑oriented DevOps, where observability plays a critical role in detection and response. Training here helps you extend MOE skills into the security domain.
- SRESchool – Dedicated to SRE practices, SLO/SLI design, and reliability engineering. Their courses and content align strongly with MOE for people focused on site reliability.
- AiOpsSchool / DataOpsSchool / FinOpsSchool – These institutions focus on AIOps, DataOps, and FinOps respectively, where telemetry and observability data are key inputs. Combining their programs with MOE helps you build advanced, data‑driven operations capabilities.
FAQs – Observability Engineering Career and MOE
Here are 12 broader FAQs about observability engineering and the MOE‑style path.
1. Is Observability Engineering only for SREs?
No. While SREs are heavy users of observability, DevOps engineers, platform teams, application developers, security engineers, data engineers, and FinOps practitioners all rely on high‑quality telemetry.
2. How difficult is Master in Observability Engineering?
If you already know basic DevOps and monitoring, MOE is challenging but manageable. The main difficulty is not tools but learning to think in terms of signals, correlations, and system behavior.
3. How long does it take to prepare?
Most working professionals can prepare effectively in 30–60 days with consistent effort, hands‑on labs, and a small project. If you are very experienced, a 7–14‑day intensive plan is feasible.
4. Do I need to be a programmer?
You should know at least one programming language and be comfortable reading code, adding instrumentation, and working with configuration/scripts. You do not need to be a full‑time developer, but scripting and debugging skills are important.
5. Is cloud experience mandatory?
You can start with on‑premise or simple environments, but cloud and Kubernetes knowledge will significantly increase the value of MOE for you. The course content explicitly covers cloud‑native observability.
6. What career outcomes can I expect?
After MOE, many professionals move into or grow within roles like SRE, Observability Engineer, DevOps Engineer, Platform Engineer, and Reliability Architect. It also strengthens your profile for engineering leadership roles.
7. Is observability different from monitoring?
Yes. Monitoring often focuses on predefined dashboards and alerts, while observability is about instrumenting systems so that you can answer new, unknown questions using telemetry. MOE focuses strongly on this broader mindset.
8. How does MOE complement Master in DevOps Engineering (MDE)?
MDE teaches you to build and run modern DevOps ecosystems (CI/CD, IaC, automation), while MOE teaches you to see and understand how those ecosystems behave in production. Together, they make you an end‑to‑end DevOps/SRE architect.
9. Is this certification recognized globally?
DevOpsSchool and its ecosystem have a global learner base and strong industry orientation; their certifications are widely used by professionals across regions, including India, US, and Europe. Recognition comes from the depth of skills you demonstrate on real projects.
10. Do I need prior certifications before MOE?
You do not strictly need prior certifications, but having DevOps, SRE, or cloud fundamentals (or MDE/DCP/SRECP‑type credentials) will make the learning smoother and quicker.
11. Does MOE include hands‑on labs?
Yes. The official curriculum emphasizes labs, demos, and practical exercises such as setting up observability stacks, instrumenting applications, and troubleshooting production‑style scenarios.
12. How do I decide if observability is the right specialization for me?
If you enjoy debugging complex issues, understanding system behavior, working across teams, and connecting technical metrics to business outcomes, observability is an excellent specialization. It sits at the intersection of DevOps, SRE, data, and architecture.
FAQs – Master in Observability Engineering (MOE) Specific
Now, here are 8 focused FAQs specifically about Master in Observability Engineering.
1. What exactly is covered in the MOE syllabus?
The syllabus includes observability fundamentals, telemetry (metrics/logs/traces), OpenTelemetry, major observability tools, cloud‑native observability, incident management, and advanced analytics.
2. Is the program more theoretical or practical?
The program is heavily practical, with labs, demos, and real‑world case‑study style exercises designed to mirror production environments.
3. What background is ideal for enrolling?
Ideal candidates have 1–3+ years in DevOps, SRE, operations, or backend development, plus some exposure to Linux, networking, and monitoring tools.
4. Can freshers take MOE?
Freshers can join, but they may find it intense. It is better to first build basic DevOps/cloud skills or pursue foundation‑level training before attempting an advanced “Master”‑level certification.
5. How is MOE delivered (mode and duration)?
DevOpsSchool offers MOE as live instructor‑led online training, self‑paced video learning, and corporate batches. Typical duration is about 15–20 hours of training time plus additional self‑study.
6. What project should I build while doing MOE?
A strong project is to take a microservices or multi‑tier application, deploy it to Kubernetes or cloud VMs, and implement full observability—metrics, logs, traces, dashboards, SLOs, alerts, and incident runbooks.
7. How is the assessment done?
The ecosystem commonly uses a combination of practical assignments, capstone projects, and evaluation tests to validate real skills, not just theory.
8. What is the best next step after completing MOE?
You can either deepen into end‑to‑end DevOps architecture with MDE, specialize into security with DevSecOps certification, or move toward SRE/DevOps leadership paths.
Conclusion
Observability Engineering is becoming a core pillar of modern DevOps, SRE, and cloud‑native operations, and the Master in Observability Engineering (MOE) certification gives you a structured, hands‑on path to master it. By combining strong telemetry design with tools like Prometheus, Grafana, ELK, CloudWatch, and OpenTelemetry, you can transform how your teams detect, understand, and resolve issues in production.If you align MOE with the right learning path—DevOps, SRE, DevSecOps, AIOps/MLOps, DataOps, or FinOps—you can accelerate your career toward high‑impact roles such as SRE, Platform Engineer, Observability Engineer, or Engineering Manager.